Tabla de contenidos
- Introducción
- Flujo de trabajo metodológico
- Paso 1: Preparación de datos
- Paso 2: Selección del Conjunto de Datos Mínimo (MDS) usando PCA
- Paso 3: Asignación de Pesos usando AHP
- Paso 4: Funciones de Puntuación
- Paso 5: Cálculo del Índice de Calidad del Suelo (SQI)
- Paso 6: Visualización de Resultados
- Interpretación de Resultados
- Reflexiones Finales
- Referencias
Introducción
Para manejar la complejidad y los múltiples aspectos de las propiedades del suelo, los investigadores y profesionales utilizan el índice de calidad de suelo (SQI) como herramienta clave. El objetivo principal del SQI es combinar diversos indicadores físicos, químicos y biológicos del suelo en una única puntuación global sin unidades. Esta agregación simplifica los datos complejos y multivariantes, lo que permite generar una métrica clara y fácil de entender que facilita la toma de decisiones de gestión informadas.
Hace un tiempo se trabajó una aplicación usando R junto con Shiny con el objetivo de crear un entorno amigable que permita realizar el cálculo del SQI e inclusive realizar interpolación para generar un mapa de superficie de éstos valores. Ahora, luego de realizar una profunda revisión de estudios recientes, he visto que usan el análisis de componentes principales (PCA) y el proceso jerárquico analítico (AHP) para establecer un conjunto de datos mínimo (MDS) y evaluar las propiedades físicas y químicas clave que afectan a la calidad del suelo, junto con el factor de ponderación asociado a cada indicador [1]. Todo esto me motivó al desarrollo del paquete de R soilquality.
Las características principales de soilquality son:
- Selección automática del Conjunto de Datos Mínimo (MDS): Reducción de dimensionalidad basada en Análisis de Componentes Principales (PCA).
- Sistema de ponderación experta: Metodología del Proceso Analítico Jerárquico (AHP) con validación del índice de consistencia.
- Funciones de puntuación flexibles: Múltiples métodos de normalización para diferentes propiedades del suelo
- Visualización integral: Múltiples tipos de gráficos para interpretación de resultados
Flujo de trabajo metodológico

Primero debemos de instalar el paquete soilquality desde el repositorio de GitHub empleando pak de preferencia:
# Instalar soilquality
pak::pak("ccarbajal16/soilquality")Paso 1: Preparación de datos
# Cargar el paquete
library(soilquality)
# Leer datos desde un archivo CSV
soil_data <- read_soil_csv("data/datos_suelo.csv")Es necesario estandarizar los datos numéricos:
# Estandarizar columnas numéricas (z-score)
datos_std <- standardize_numeric(soil_data, exclude = "SampleID")
# Esto centra y escala los datos para el análisis PCAPaso 2: Selección del Conjunto de Datos Mínimo (MDS) usando PCA
El conjunto de datos mínimo (MDS) es un subconjunto de indicadores del suelo que mejor representa la calidad general del suelo. El PCA nos ayuda a identificar las variables más importantes que explican la mayor variabilidad en los datos.
# Definir las propiedades a analizar
propiedades <- c("Sand", "Silt", "Clay", "pH", "OM", "P", "K", "CEC", "BD")
# Seleccionar solo las propiedades que se quieren analizar
soil_subset <- datos_std[, propiedades]
# Aplicar PCA para seleccionar MDS
# La función retiene componentes principales que explican al menos 5% de varianza
resultado_mds <- pca_select_mds(
data = soil_subset,
var_threshold = 0.05, # Umbral mínimo de varianza explicada
loading_threshold = 0.5 # Umbral de carga para selección
)
# Ver las variables seleccionadas en el MDS
print(resultado_mds$mds)
# Ver la varianza acumulada
cumsum(resultado_mds$var_exp)Paso 3: Asignación de Pesos usando AHP
El proceso analítico jerárquico (AHP), es un método de toma de decisiones multicriterio que permite asignar pesos a los indicadores basándose en comparaciones pareadas de su importancia relativa. Los expertos comparan cada par de indicadores usando la escala de Saaty (1-9)
| Valor | Significado |
| 1 | Igual importancia |
| 3 | Importancia moderada |
| 5 | Importancia fuerte |
| 7 | Importancia muy fuerte |
| 9 | Importancia extrema |
| 2,4, 6, 8 | Valores intermedios |
Crear matriz AHP de forma interactiva
# Definir los indicadores del MDS
indicadores_mds <- resultado_mds$mds
# Crear matriz de comparación pareada interactivamente
# El sistema guiará al usuario a comparar cada par
matriz_ahp <- create_ahp_matrix(
indicators = indicadores_mds,
mode = "interactive"
)
# El sistema mostrará prompts como:
# Compare 'Sand' vs 'Clay'
# How much more important is 'Sand' compared to 'Clay'?
# Usuario responde con un valor de 1-9
# Exportar matriz AHP a CSV
write.csv(matriz_ahp$matrix, "matriz_ahp.csv", row.names = FALSE)De manera automática va realizar una análisis de consistencia (CR), donde un CR < 0.10 indica que las comparaciones son consistentes y los pesos son confiables.
Paso 4: Funciones de Puntuación
El paquete ofrece diferentes métodos para transformar valores de propiedades del suelo a puntuaciones (0-1):
A. Función Lineal: Más es Mejor (higher_better)
La función score_higher_better() se utiliza cuando la calidad del suelo presenta una mejora continua a medida que aumenta el valor del indicador evaluado. A diferencia de otras funciones, no se establece un valor óptimo ni un umbral crítico más allá del cual el indicador genere efectos adversos. Esta función asume una relación proporcional y monótona creciente entre el indicador y la calidad edáfica, siendo apropiada para propiedades como el contenido de materia orgánica, la capacidad de intercambio catiónico o la disponibilidad de nutrientes esenciales.
En otras palabras, cada aumento unitario en las propiedades del suelo contribuye por igual a mejorar la calidad del suelo.
# Aplicar a datos de materia orgánica
score_mo <- score_higher_better(
x = soil_data$OM,
min_val = 0.5,
max_val = 5
)
# Valores mínimos reciben 0, valores máximos reciben 1B. Función Lineal: Menos es Mejor (lower_better)
La función score_lower_better() se utiliza cuando el indicador evaluado representa una condición de estrés, limitación o degradación del suelo. Bajo este esquema, valores mayores del indicador se asocian con una reducción de la calidad edáfica. Este comportamiento es típico de propiedades que reflejan limitaciones físicas (como la densidad aparente o la resistencia a la penetración) o la acumulación de elementos tóxicos (como sales solubles o metales pesados).
# Aplicar a datos de densidad aparente
puntuaciones_da <- score_lower_better(
x = soil_data$BD,
min_val = 1.0,
max_val = 1.9
)
# Valores máximos reciben 0, valores mínimos reciben 1C. Función No Lineal: Rango Óptimo (optimum_range)
La función score_optimum(), se emplea cuando la calidad del suelo alcanza su valor máximo en un punto intermedio, disminuyendo progresivamente cuando el indicador se aleja de este óptimo, ya sea por valores superiores o inferiores. Este patrón refleja la naturaleza de múltiples procesos biológicos y químicos del suelo que requieren condiciones específicas para su funcionamiento adecuado.
El pH constituye el ejemplo más común: valores extremadamente ácidos (pH < 5.0) limitan la disponibilidad de nutrientes esenciales y aumentan la toxicidad de elementos como aluminio y manganeso, mientras que valores alcalinos (pH > 8.0) reducen la disponibilidad de micronutrientes (Fe, Mn, Zn, Cu) y pueden inducir deficiencias nutricionales. El rango óptimo (generalmente pH 6.0-7.0 para la mayoría de cultivos) maximiza la disponibilidad de nutrientes, la actividad microbiana y la mineralización de la materia orgánica.
# Aplicar a datos de pH
score_ph <- score_optimum(
valores = soil_data$pH,
optimal = 6.5,
tolerance = 1.0
penalty = "quadratic" # linear or quadratic
)
# pH = 6.5 recibe puntuación 1.0
# pH fuera del rango 5.5-7.5 recibe puntuaciones menoresLa penalización («penalty») es una función de pérdida aplicada a la desviación del valor óptimo, convertida en una puntuación. Con la penalización lineal, la puntuación disminuye a un ritmo constante a medida que se aleja del valor óptimo. Con la penalización cuadrática, la puntuación disminuye lentamente cerca del valor óptimo (ya que al elevar al cuadrado un número pequeño se reduce), pero con mayor intensidad a medida que se acerca al límite de tolerancia.
# Visualizar functiones de penalización
ph_range <- seq(4, 9, by = 0.1)
scores_linear <- score_optimum(ph_range, 6.5, 1.5, "linear")
scores_quad <- score_optimum(ph_range, 6.5, 1.5, "quadratic")
plot(ph_range, scores_linear, type = "l", col = "blue",
xlab = "pH", ylab = "Score", main = "Optimum Range Scoring",
ylim = c(0, 1))
lines(ph_range, scores_quad, col = "red")
abline(v = 6.5, lty = 2, col = "gray")
legend("topright", c("Linear", "Quadratic", "Optimum"),
col = c("blue", "red", "gray"), lty = c(1, 1, 2))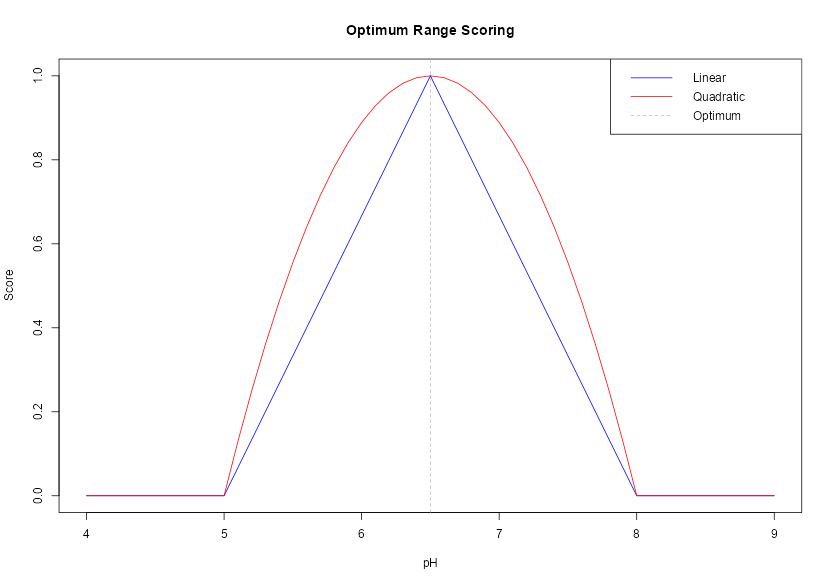
El método cuadrático otorga puntuaciones más altas que el lineal para la misma desviación; es decir, es más tolerante, excepto en los puntos finales (ambos dan 1 en el óptimo y 0 en la tolerancia).
Significado práctico en los indicadores de suelo:
Lineal: se busca que las desviaciones afecten de forma inmediata y proporcional.
Cuadrático: se aceptan las desviaciones moderadas como «en general aceptables», pero se busca castigar las desviaciones grandes a medida que se acerca al límite.
D. Función No Lineal: Umbrales Personalizados (threshold_scoring)
La función score_threshold() es empleado cuando la relación entre el indicador y la calidad del suelo no es continua, sino que presenta cambios discretos en niveles críticos definidos. Este método establece múltiples umbrales basados en criterios agronómicos o ecológicos, asignando puntuaciones específicas a cada intervalo. Las implicaciones principales son: (i) permite incorporar conocimiento experto sobre niveles críticos de suficiencia o toxicidad; (ii) reconoce que pequeños incrementos del indicador por debajo de un umbral pueden no mejorar la calidad del suelo; (iii) captura transiciones abruptas en la funcionalidad edáfica, como el paso de deficiencia severa a disponibilidad adecuada de nutrientes. Esta función es particularmente apropiada para nutrientes con niveles críticos establecidos (P, K, micronutrientes) o contaminantes con umbrales de toxicidad definidos.
# Aplicar a datos de fósforo
score_p <- score_threshold(
x = soil_data$P,
thresholds = c(0, 10, 20, 50, 100),
scores = c(0, 0.25, 0.50, 0.80, 1.0)
)
# P < 10 ppm: muy bajo (0.0-0.25)
# P = 20 ppm: bajo (0.50)
# P = 50 ppm: medio (0.80)
# P > 100 ppm: óptimo (1.0)Podemos aplicar puntuaciones a múltiples indicadores:
# Definir reglas personalizadas para cada indicador
custom_rules <- list(
pH = optimum_range(optimal = 6.5, tolerance = 1.0),
OM = higher_better(),
Sand = optimum_range(optimal = 40, tolerance = 10),
Clay = optimum_range(optimal = 30, tolerance = 10),
K = threshold_scoring(
thresholds = c(0, 80, 150, 250),
scores = c(0.0, 0.4, 0.7, 1.0)
),
BD = lower_better()
)
# Aplicar todas las reglas a los datos
scoring_data <- score_indicators(
data = soil_data,
mds = indicadores_mds,
directions = custom_rules
)
# Ver matriz de algunas puntuaciones transformadas
head(scoring_data [, c("pH", "OM", "K","OM_scored", "pH_scored", "K_scored")])
pH OM K OM_scored pH_scored K_scored
1 7.0 2.46 131 0.3406593 0.5 0.6185714
2 6.2 2.29 121 0.2939560 0.7 0.5757143
3 5.0 2.49 106 0.3489011 0.0 0.5114286
4 5.6 2.88 113 0.4560440 0.1 0.5414286
5 4.9 4.24 118 0.8296703 0.0 0.5628571
6 4.8 2.72 40 0.4120879 0.0 0.2000000En resumen, se pueden utilizar ecuaciones lineales y no lineales para evaluar el SQI con base a diversas propiedades del suelo, pero son las propiedades biológicas las más determinantes para evaluar el impacto de la cambio de uso del suelo sobre el valor de su calidad [2].
Paso 5: Cálculo del Índice de Calidad del Suelo (SQI)
Se puede realizar el flujo de trabajo completo automatizado:
resultado_sqi <- compute_sqi_properties(
data = soil_data,
properties = names(soil_subset),
id_column = "SampleID",
pairwise_matrix = matriz_ahp$matrix, # Matriz AHP del Paso 3
scoring_rules = custom_rules # Reglas del Paso 4
)
# Ver resultados del SQI
print(resultado_sqi)
# Exportar resultados a CSV
write.csv(resultado_sqi$results, "sqi_results.csv", row.names = FALSE)Paso 6: Visualización de Resultados
Generación de gráficos de distribución del SQI
# Histograma de la distribución de SQI
plot(resultado_sqi, type = "distribution")
# Muestra la frecuencia de valores SQI en todas las muestras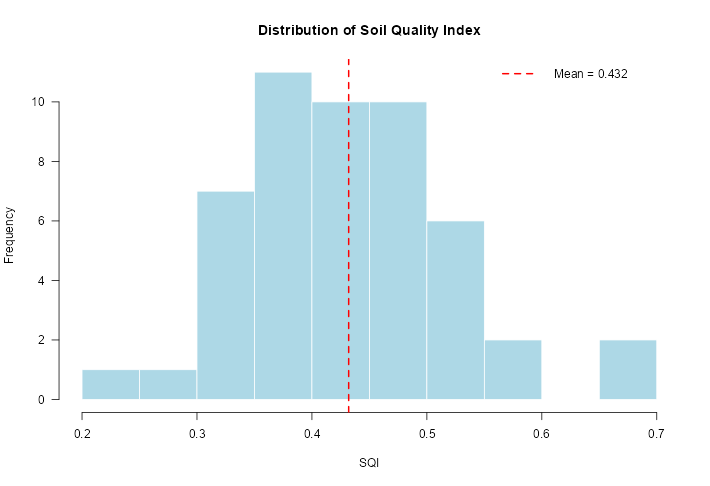
# Gráfico Biplot
plot(resultado_sqi, type = "biplot")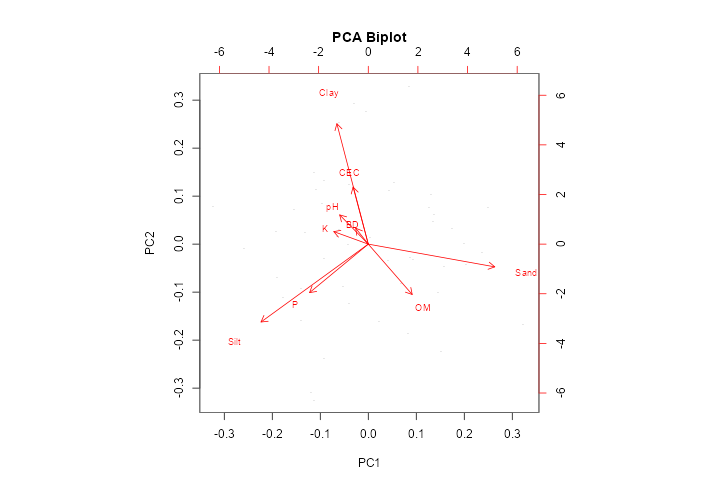
Podemos generar un reporte completo multipanel
# Generar un reporte visual completo
plot_sqi_report(resultado_sqi)
# Incluye:
# - Distribución del SQI
# - Pesos de indicadores
# - Puntuaciones por muestra
# - Estadísticas descriptivas
# Resumen estadístico
summary(resultado_sqi$results$SQI)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2429 0.3670 0.4377 0.4320 0.4938 0.6739 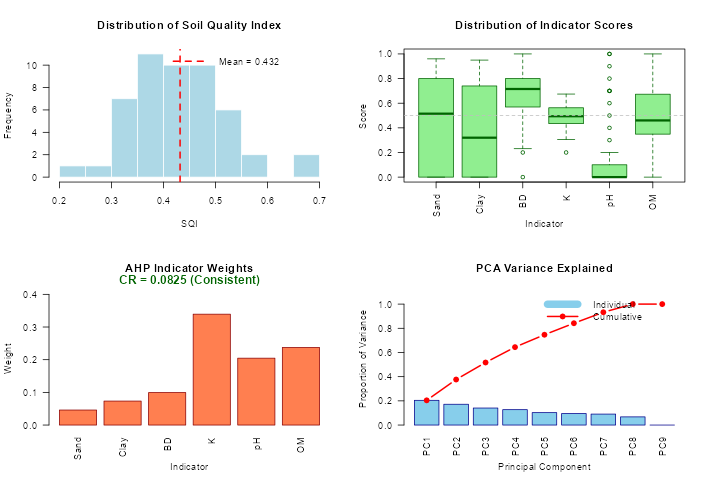
Interpretación de Resultados
Se podría generar una tabla para interpretar los resultados.
| Rango SQI | Categoría | Interpretación |
|---|---|---|
| 0.80 – 1.00 | Excelente | Suelo de muy alta calidad, óptimo para cultivos |
| 0.60 – 0.79 | Bueno | Suelo de buena calidad, adecuado para la mayoría de cultivos |
| 0.40 – 0.59 | Moderado | Calidad moderada, requiere manejo para mejorar |
| 0.20 – 0.39 | Bajo | Baja calidad, necesita intervención significativa |
| 0.00 – 0.19 | Muy Bajo | Calidad muy baja, limitaciones severas |
Reflexiones Finales
El paquete soilquality proporciona un grupo de funciones que nos permite evaluar de manera robusta y flexible la calidad del suelo a través de métodos cuantitativos. La integración de PCA para la selección de MDS y AHP para la ponderación de indicadores garantiza un enfoque científicamente fundamentado que puede adaptarse a diferentes contextos edáficos y objetivos de manejo.
Una importante fase de este proceso de cálculo radica en la utilización de funciones de puntuaciones lineales y no lineales. Esto nos permite capturar la compleja relación entre propiedades del suelo y su calidad funcional, lo que nos demuestra la flexibilidad del paquete, pero también su robustez para establecer relaciones y puntuaciones específicas para cada propiedad del suelo. Finalmente el poder contar con herramientas de visualización, nos facilita la comunicación de los resultados finales.
Existe algunas funciones del paquete que no fueron exploradas pero que podrían implementarse. Espero que una vez practicado los scripts presentados, podamos profundizar en otras opciones un poco más complejas.
Referencias
- Ibrahim, H. M., Alasmary, Z., Majrashi, M. A., Harbi, M. A., Abldubise, A., Alghamdi, A. G., Ibrahim, H. M., Alasmary, Z., Majrashi, M. A., Harbi, M. A., Abldubise, A., & Alghamdi, A. G. (2025). Application of Principal Component and Multi-Criteria Analysis to Evaluate Key Physical and Chemical Soil Indicators for Sustainable Land Use Management in Arid Rangeland Ecosystems. Land, 14(11). https://doi.org/10.3390/land14112167
- Pouladi, N., Jafarzadeh, A.A., Shahbazi, F. et al. Assessing the soil quality index as affected by two land use scenarios in Miandoab region. SN Appl. Sci. 2, 1875 (2020). https://doi.org/10.1007/s42452-020-03651-9